
Software Reliability
Introduction
소프트웨어는 장비나 시스템의 매우 넓은 분야의 운용시스템의 일부분이다.
만약 어떤 기능을 수행하는 소프트웨어에 에러가 있다면, 그 기능을 수행할 때마다 고장이 날 것이다. 따라서 소프트웨어의 에러는 매우 치명적인 문제가 될 수 있다. 하드웨어와 소프트웨어의 신뢰도의 차이점은 다음과 같다.
| Hardware | Sofrware |
| 고장은 설계, 제작, 사용, 정비상 결함으로 발생할 수 있다. | 고장은 거의 설계상 에러에 의해 발생한다. 나머지는 무시할만 하다. |
| 고장은 마모에 의해 발생할 수 있으며 가끔은 고장이 발행하기 전에 경고를 나타낸다. | 마모에 의한 고장은 없으며, 경고없이 고장이 발생한다. |
| 수리는 보다 신뢰성 있는 장비에 의해 이뤄진다. | 유일한 수리 방법은 재설계이다. |
| 신뢰도는 burn-in과 마모 현상과 연관된다. | 신뢰도는 운용시간과는 관계가 없다. |
| 고장은 운용시간의 경과에 연관이 있다 | 에러가 실행되는 프로그램 단계에서 고장이 발생한다. |
| 신뢰도는 환경 팩터와 연관이 있다. | 프로그램 입력에 영향을 주는 경우를 제외하고는 환경 팩터와 연관이 없다. |
| 신뢰도는 설계와 사용 팩터의 지식으로 이론적으로 예측할 수 있다. | 신뢰도는 전적으로 설계시의 휴먼 팩터에 의존하므로 물리적 방법으로는 예측할 수 없다. |
| 신뢰도는 가끔 redundancy에 의해 개선될 수 있다. | |
| 고장은 어떤 패턴을 가지고 발생하는 부품에 의해 발생할 수 있으며, 부품에 가해지는 스트레스, 다른 팩터로부터 예측되어질 수 있다. 치명적인 부품 리스트와 파레토 분석은 유용한 기법이다. |
에러는 프로그램 전범위에서 랜덤하게 존재한다. 치명적 부품 리스트와 파레토 분석은 적합하지 않다. |
Software Failure Mode
Specification errors
전형적으로 에러의 절반이상은 소프트웨어 게발 중 명세(specification)를 기록하는 와중에 생긴다.
소프트웨어는 물리적 방식으로 인식이 불가능하기 때문에 애매모호함, 모순, 불완전한 표현에 대한 해석이 어느 정도는 상식적인 범위에 있다. 따라서 소프트웨어 명세 개발 과정과 검토는 매우 주의깊게 이루어져야 한다.
프로그램은 요구사항을 정확하게 반영해야 한다. 소프트웨어 설계에는 하드웨어 설계같은 안전 이득이 없다.
명세는 이론적으로 완벽해야한다. 만일 아래와 같은 표현이 있다하자.
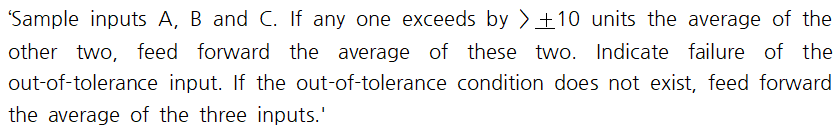
위 표현의 다이어그램은 아래와 같다.

이 경우에 B와 C가 나머지 두 개의 평균값보다 10이 넘게 차이가 나기 때문에, 두 개의 잘못된 경우가 있지만 C보다 먼저 B를 비교하는 과정이 있기 때문에 프로그램은 B가 고장이라고 나타낼 것이다. 이 명세는 입력이 tolerance를 넘을 경우를 모두 표시할 수 없도록 표현되었으며, 명세 기술자가 진정 바라는 바를 다 커버할 수가 없다. 소프트웨어 명세는 모든 가능한 입력 상황과 원하는 출력을 커버해야 하기 때문에 하드웨어 명세보다 보다 신중함이 요구된다.
명세는 하드웨어의 능력을 넘어서는 정확도, 속도의 시험할 수 없는 요구사항을 포함해서는 안된다.
Software system design
소프트웨어 신뢰도 설계에서 중요한 특징은 robustness이다. 이 용어는 에러 상황에서 심각한 영향 없이 프로그램이 버텨내는 능력을 표현한다.
Software code generation
전형적인 프로그램은 많은 수의 코드 표현을 포함하고 있기 때문에 코드 생성은 에러의 가장 큰 원인이다.
일어날 수 있는 전형적인 에러는,
1. 오식(Typographical errors)
2. 부정확한 수식 값
3. 심볼의 누락
4. 0으로 나누는 것 같은 애매한 표현을 포함하는 것
Software Structure and Modularity
Structure
프로그램 에러의 큰 원인은 loops와 branches와 같은 구조에서의 GOTO 형식이다. 구조화된 프로그램 접근은 하나의 입구에 하나의 출구만을 갖는 관리 구조를 사용함으로서 GOTOs의 사용을 억제한다.
예를 들어 아래 그림에 비구조화된, 구조화된 방법을 도시하였다.

비구조화된 접근에서는 잘못된 line number가 주어지면 에러를 유발시킬 수 있고, subroutine에서 decision point로의 자취를 찾기가 힘들다.
반면 구조화된 접근에서는 line number 에러의 가능성을 제거하고, 이해하고 점검하기가 보다 쉽다.
구조화된 프로그램은 보다 작은 에러가 나게 하고, 명확하고, 정비를 보다 쉽게 한다.
반면 구조화된 프로그램은 스피드와 메모리 요구면에서 보다 덜 효과적이다.
Modularity
모듈화된 프로그램은 프로그램 요구사항을 몇 개의 보다작은 프로그램 요구사항(or 모듈)로 나눠서 각각 따로 특정되게 구분되고 씌여지고 점검된다.
세분화된 모듈은 보다 짧은 시간에 씌여지고 점검되며, 가동중인 프로그램의 변환 가능성을 줄여준다.
각각의 모듈 명세는 각 모듈이 프로그램의 다른 부분과 어떻게 interface되어 있는지 표현해야한다.
따라서 모든 입력과 출력은 명확히 명시되어야 한다.
구조화된 프로그램은 프로그램 구조, 모듈명세를 쓰는 것, 점검 요구사항의 사전 작업이 보다 많이 포함되어 있다.
하지만 어떤 프로그램 개발에 있어서의 기본 원리인 이러한 노력은, 프로그램 기술과 디버깅에 소요되는 전체적인 시간을 줄임으로서 보다 나중에 보상되어진다. 또한 프로그램 이해와 변환을 보다 쉽게 하여준다.
보다 쉽고 명확하게 수정되는 프로그램의 능력은 하드웨어의 정비성과 비교될 수 있다.
모듈의 최적화된 사이즈는 모듈의 기능에 연관되며, 프로그램 구성요소의 개수에 의해서만 결정되지는 않는다. 사이즈는 보통 적정한 interface의 위치에 의한 정도에 의해 결정된다.
첫째로 내세울 수 있는 룰은 모듈은 고급언어로 코드 라인이 보통 100줄을 넘지 않는다는 것이다.
Requirements for structured and modular programming
많은 소프트웨어 구매자들은 신뢰성과 정비성의 문제 때문에 구조적이고 모듈화된 프로그램의 필요성에 대해 구체적으로 표현한다.
영국에서는 MASCOT(Modular Approach to Software Construction Operation and Test), 미국에서는 APSE(Ada Programming and Support Environment)가 과거에 사용된 비구조적 접근 방법과의 많은 차이점과 비용측면의 차이점에 대한 확인을 제공하는 방법이다.
Programming Style
프로그램 스타일은 프로그램 설계, 코딩에 접근하는 방법의 표현이다. 구조화되고 모듈화된 프로그래밍도 스타일의 한 측면이다. 명백히 규칙이 있는 프로그래밍 스타일은 소프트웨어 신뢰도와 정비도에 큰 영향을 미칠 수 있으며, 설계 가이드, 설계 검토, 프로그래머 훈련에서도 매우 중요하다.
Fault Tolerance
프로그램에 심각한 고장을 유발시키지 않는 고장이 기술될 수 있다.
앞에서 robustness를 언급한 바 있다. 이것은 fault tolerance의 한 측면이다. 고장 소스의 발견은 프로그램 내부 점검이나, 주기적인 체크에 의해 발견 할 수 있다.
에러가 발생했을 때 프로그램을 안전한 상태로 만드는 안전도(safety)라는 중요한 팩터가 있다. Fault tolerance는 프로그램 리던던시에 의해서도 생긴다. 높은 무 결점 시스템을 위하여 동시에 구동할 수 있도록 나누어진 코드로 정렬되거나(콘트롤러에 의해 연결된), 콘트롤러의 time-sharing 방식을 사용한다. 선택된 처리순서는 사용될 출력을 선택하는데 사용된다.
이 접근 방법의 유효성은 두 개의 나누어진 코드화 된 프로그램은 같은 coding 에러를 잘 포함하지 않는다는 전제에 있다. 물론 이것이 명세 에러를 막아주는 역할을 하지는 못한다.
Software Reliability Prediction and Measurement
여기에 소개되는 방법들은 소프트웨어 엔지니어 연합에서 표준화 된 것도 아니며 일반적으로 받아들여진 것도 아니다.
The Poisson model(time-related)
이것은 코드 구조에서 에러는 랜덤하게 존재하고 에러의 발생은 프로그램이 구동될 때 시간의 함수라고 가정한다. 시간 t에서 발생하는 에러의 수는 N(t)이다
1. N(0) = 0
2. 시간 간격(t, t+dt)에서 발생하는 에러는 1개를 넘지 않는다.
3. 에러의 발생은 이전의 에러와는 독립적이다.
위와 같은 상황에서 고장의 발생은 Poisson 분포에 의해 다음과 같이 표현된다.

m(t)는 간격(0,t)에서 발생하는 에러의 평균값이다.
m(t) = a[1-exp(-bt)]
여기서 a는 총 에러 수이고, b는 상수이다.
모든 최근의 에러가 발생하고 어떤 시간 s에서 고쳐졌을 때, 신뢰도 함수는
R(t) = exp〚-a{exp(-bs)-exp[-b(s+t)]}〛이다.
하지만 소프트웨어의 에러는 하드웨어 고장 프로세스처럼 시간에 연관되어 발생하는 것이 아니기에 시간에 관련된 모델은 문제가 있을 수 있다.
The Musa model
Musa 모델은 변수에 관계없이 프로그램 실행 시간을 사용한다.
간략화 된 Musa 모델은 다음과 같다.

여기서 No는 에러의 고유 수이며, To는 시작시점의 MTTF이며, C는 ‘testing compression factor'이며 이것은 운용시간과 시험시간의 비와 같다.
MTTF는

The Jelinski-Moranda and Schick-Wolverton models
두 개의 다른 지수타입 모델로는 Jelinski-Moranda(JM) model과 Schick-Wolverton(SW) model이 있다.
JM, SW 모델에서 hazard function h(t)는 각각 다음과 같다.

Littlewood models
littlewood는 다른 프로그램 에러는 유발된 고장의 다른 확률 값을 갖는다는 사실에 주의한다.

MIL-HDBK-338B
Prediction Model

In-house Historical data collection model
어떤 조직에서는 그들의 소프트웨어 프로젝트를 수행하며 얻어진 정보의 DB를 모으고 사용함으로써 소프트웨어 신뢰도를 예측한다.
Musa's execution time model

Putnam's model
Trachtenberg와 Gaffney는 여러 가지 사이즈와 타입의 많은 프로젝트의 개발 과정의 관점에서 결함의 history를 조사했다. 이러한 활동에 바탕을 두고 Putnam은 관찰된 신뢰도가 Rayleigh 분포를 따른다고 특정 지었다.


계산 결과는 아래 표, 그림과 같다.
t는 달수고, f(t)는 관찰된 달의 결함 수의 부분이며, F(t)는 누적된 부분을 나타낸다.
표에서 보듯이 10개월이 지나면 milestone 7이 되며, 13개월이 지나면 milestone 8이 되지만 15개월이 지나도 milestone 9를 만족하지 못한다.

이 모델의 큰 장점은 Musa 모델이 테스트 시작 시점에서만 예측 가능한데 반해, 개발 프로세서상의 여러 지점에서 고장의 수를 예측할 수 있다는데 있다.
이 모델의 다른 결과로는 1/f(t)에 의해 다음 결함까지의 평균 시간(MTTD)을 구할 수 있다는 것이다. 이것은 milestone 4 이후에야 의미가 있다. 왜냐하면 그 전에는 시스템이 결함을 발견 할만큼 개발이 되어 있지 않기 때문이다. 개발 프로세서가 진행되면서(시간이 지나면서) 결함이 제거되기 때문에 MTTD는 증가한다.
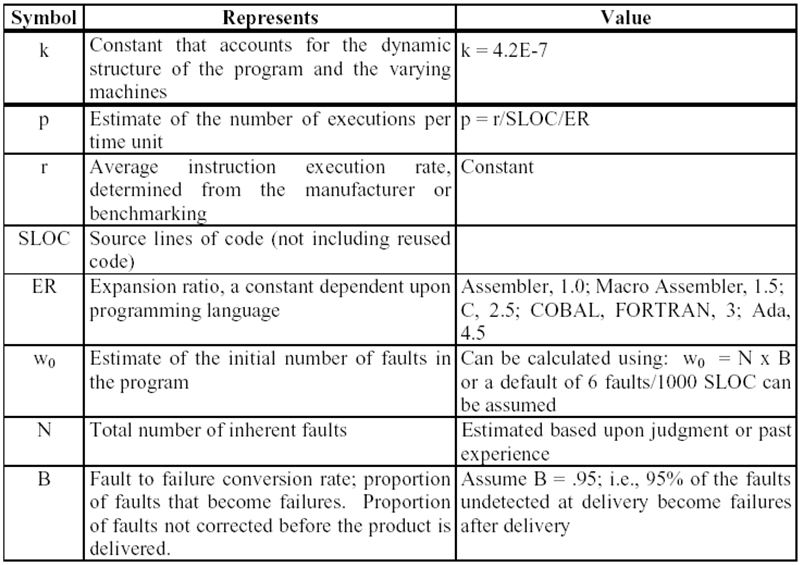
Rome laboratory prediction model : RL-TR-92-52
이것은 delivery time(Putnam 모델의 milestone 6)에서의 고장 밀도를 예측하고, 이 고장 밀도를 이용하여 고유 고장의 총 개수(N)와 고장율을 구하는 방법이다.
이 모델의 용어는 다음 표와 같다.

예측은 공군에서 개발된 여러 타입의 소프트웨어에서 수집된 데이터에 근간을 둔다.
아래 표를 참고한다.

기본 식은 다음과 같다.
Faulty Density = FD = A*D*S(faults/line)
Estimated Number of Inherent Faults = N = FD*SLOC
Failure Rate = FD*C(faults/time)
이 모델은 소프트웨어의 고장 밀도를 예측하는데 사용되는 팩터로 구성되며, 팩터는 아래와 같다.

이 모델의 이점은 다음과 같다.
1. 소프트웨어의 concept이 알려지면 바로 사용할 수 있다.
2. Concept 단계동안 고장 밀도의 개발 환경 영향을 결정할 수 있는 "what-if" 분석을 허용한다
3. 설계 단계동안 고장 밀도의 소프트웨어 특성의 영향을 결정할 수 있는 "what-if" 분석을 허용한다.
4. 이 예측방법은 소프트웨어 시스템을 구성한 각각의 타입에 적용할 수 있기 때문에 소프트웨어 고장율 할당을 할 수 있다.
5. 이 예측방법은 특정한 구성 환경에서의 전까지의 소프트웨어 데이터를 이용하여 A, D, S 팩터 값을 맞출 수 있다.
반면 이 모델의 단점은 다음과 같다.
1. 팩터와 그 값들은 공군의 소프트웨어 개발에 근간을 두므로 적합한 타입이 없을 경우는 평균값을 선택한다. 공군 적용 타입은 군수 환경 이외의 소프트웨어 개발에는 잘 맞지 않는다.
2. SLOC의 사이즈 사용은 최근의 소프트웨어 개발 기술의 현 변화 면에서 점점 관련이 떨어진다.
Rome laboratory prediction model : RL-TR-92-15
이 테크니컬 리포트는 많은 소프트웨어 시스템을 검토했다.
그리고 평균 예측 고장율은 6 faults/1000 SLOC 라는 결론을 내렸다.(이것은 Musa's execution time model에서 default value for fault rate)로 사용된다.)
여기에 더하여 24개의 예측 팩터 값들은 다음 표와 같다. 이 값들은 아래의 3개의 주요 변수를 계산하는데 사용된다.
1. 각 계발 단계동안 발견된 고장 개수(DP)
2. 각 단계동안 사용된 man-hours(UT)
3. 개발품의 사이즈(S)

식은 다음과 같다.


Software Reliability Allocation
소프트웨어 신뢰도 할당 방법은 아래 표와 같이 5가지가 있다. 이것은 운용 형태나 소프트웨어의 복잡성, 실행 타입에 의해 구별되어진다.

여기서 CSCI는 Computer Software Configuration Item이다.
Equal Apportionment Applied to Sequential Software CSCIs

Equal Apportionment Applied to Concurent Software CSCIs
이 기법은 CSCI가 동시에 수행될 때 각각의 소프트웨어 CSCI의 목표 고장율을 할당할 때 사용된다. 나머지는 "Equal Apportionment Applied to Sequential Software CSCIs" 과 같다.
Allocation based on operational criticality factors
치명도가 높은 모드는 낮은 고장율의 할당이 요구된다. 낮은 고장율을 만족하기 위해선 fault-tolerance와 다른 방법들이 요구된다.
소프트웨어 CSCI 각각의 적당한 고장율 할당을 위해선 각각의 CSCI의 치명도 팩터를 알아야한다.
절차는

Allocation based on Complexity factors
소프트웨어에 적용할 복잡성의 몇 가지 타입은 아래와 같다.
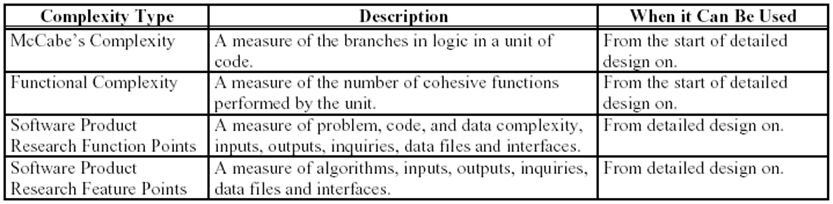
설계 단계동안 위 타입에서 적합한 타입을 골라 복잡성 팩터를 계산한다. 복잡성이 커질수록 각각의 목표 고장율을 만족시키기 위해선 보다 많은 노력이 요구된다. 결론적으로 복잡한 CSCI일수록 높은 목표 고장율이 할당되어야 한다.
복잡성 팩터가 2배라면 목표 고장율도 2배로 할당되어야 한다.
절차는

Software Testing
Module testing
모듈 테스트란 각각의 구성품(하나의 프로그램 모듈, 하나의 서브루틴)을 테스트하는 것을 말한다.
목적은 모듈의 기능이 그것의 명세와 일치하는지를 결정하기 위함이다.
모듈 테스트는 모듈 프로그래머에 의해 행해지며 프로그래머의 구성요소의 테스트, 문제 발견, 디버깅, 재 테스트의 반복적인 과정이 될 수도 있다. 그래서 간혹 모듈 테스트를 하나의 테스트 과정이 아니라 방법으로만 고려하기도 한다.
Integration testing
모듈 테스트 후에 소프트웨어 테스트 과정은 integration 테스트이다. 이 활동은 완전한 시스템이 완료될 때까지 순서대로 구성요소들의 결합을 포함한다.
다른 구성요소간의 상호 작용과 그들간의 interface에 중점을 둔다.
매우 자주 프로그래밍 그룹은 integration 테스트를 수행한다.
Integration 테스트를 계획할 때 각각의 모듈을 결합하는데 사용되는 과정의 결정이다.
여기는 non-incremental과 incremental 테스트의 두 가지 접근 방법이 있다.
Non-incremental integration 테스트는 모든 구성요소들을 한번에 결합하고 테스트를 시작하는 것이다. 모든 모듈을 한꺼번에 결합했기 때문에 고장은 여러 가지 상호 작용 중 어느 것이 표현될 것이다.
추천하는 접근법은 incremental 테스트이다. 이 방법을 위하여 하나의 구성요소는 완전히 모듈 테스트되고 디버깅되어 있어야 한다. 다른 구성요소는 첫 번째 구성요소에 결합되어 테스트되고 디버깅된다.
Incremental 테스트에는 각 모듈들을 어떤 순서대로 결합시켜야 하나라는 문제가 있다. 이것을 명확히 구분하는 방법은 없다. 테스터는 시스템에서 어떤 것이 가장 민감하게 반응하는가의 지식을 가지고 있어야한다. Top-down과 bottom-up의 두 가지 방법이 있다.
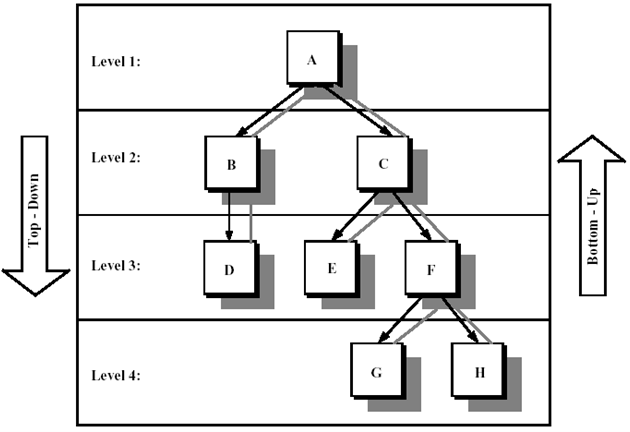
* 참고

(End)
'02 RAM Analysis' 카테고리의 다른 글
| IEC 1164, Reliability Growth - Statistical Test and Estimation Methods (0) | 2022.10.28 |
|---|---|
| NSWC-98/LE1 (0) | 2022.10.28 |
| Reliability Prediction and Modeling (0) | 2022.10.27 |
| Capacitor Reliability Prediction Example (0) | 2022.10.24 |
| UAS(Unmanned Aircraft System) Reliability (0) | 2022.09.23 |




댓글